从6.7或更早版本直接升级到7.5.1需要 完全重启群集。
python client通过token连接k8sAPI cluster
1、创建一个k8s admin-user1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23kubectl apply -f - <<EOF
---
#在kube-system下创建admin-user
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kube-system
---
#给admin-user cluster-admin权限
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kube-system
EOF
查看k8sCluster APIURL地址1
kubectl config view --minify | grep server | cut -f 2- -d ":" | tr -d " "
获取刚刚创建的admin-user token在把base64解密出来的token
示例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24from kubernetes import client, config
#see https://kubernetes.io/docs/tasks/administer-cluster/access-cluster-api/#accessing-the-cluster-api to know how to get the token
#The command look like kubectl get secrets | grep default | cut -f1 -d ' ') | grep -E '^token' | cut -f2 -d':' | tr -d '\t' but better check the official doc link
aToken="eyJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLXhsZnF3Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiI5MmEzN2JkNi1hYjg5LTExZTktODkyMi0wODAwMjdlMWY4NDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.GRerIItaGUf8PV8rb3eDsmP90YZCd3BGWuYhXr_y2f4zmd59rpHfP8E6xWoHQiav84Kq1b9E8tiEHC9aoPcNmmclS8AIm95DA-QHv_5WJrJPcTB-XpzF1ccPFSdJQ0hmjw54pxQo4gQLJ1MouPiwH-sWjVM1OYiEmillvglIiFfTrc24fJj1Fu2V46lsUXLPKBVrny3v6soUjteU4IDJxjHhQodpFSBbxnYVUvaK_hvthDv_IsCcY2rQ16ii4n6tTt8vf1D0NKZv4pWeXH2sRhzQ5Q3aK8VjZAd6PBd3iVMz2Gp24KWqFoqQ9-TRgwL6oIoHT3E0qEoapDzxg9jWSA"
# Configs can be set in Configuration class directly or using helper utility
configuration = client.Configuration()
configuration.host="https://192.168.99.100:8443"
configuration.verify_ssl=False
configuration.debug = True
#Maybe there is a way to use these options instead of token since they are provided in Google cloud UI
#configuration.username = "admin"
#configuration.password = "XXXXXXXXXXX"
configuration.api_key={"authorization":"Bearer "+ aToken}
client.Configuration.set_default(configuration)
v1 = client.CoreV1Api()
print("Listing pods with their IPs:")
ret = v1.list_pod_for_all_namespaces(watch=False)
for i in ret.items:
trueprint("%s\t%s\t%s" % (i.status.pod_ip, i.metadata.namespace, i.metadata.name))
Kubernetes中的Taint和Toleration
Taint 和 toleration 相互配合,可以用来避免 pod 被分配到不合适的节点上。每个节点上都可以应用一个或多个 taint ,这表示对于那些不能容忍这些 taint 的 pod,是不会被该节点接受的。如果将 toleration 应用于 pod 上,则表示这些 pod 可以(但不要求)被调度到具有匹配 taint 的节点上。可使用节点污点来控制允许工作负载在哪些节点上运行。
添加taint
查看节点taint在返回的节点说明中,查找 Taints 字段1
kubectl describe nodes rancher-k8s-m1
可以使用命令 kubectl taint 给节点增加一个 taint。比如1
kubectl taint nodes [NODE_NAME] [KEY]=[VALUE]:[EFFECT]
还可以向具有特定标签的节点添加污点:1
2kubectl taint node -l node-role.kubernetes.io/etcd=tru dedicated=foo:PreferNoSchedule
#kubectl taint nodes dev-k8s-m1 node-role.kubernetes.io/controlplane=true:NoSchedule 给节点 dev-k8s-m1 增加一个 taint,它的 key 是 role.kubernetes.io/controlplane,value 是 true,effect 是 NoSchedule。除非pod有符合的容忍(toleration),否则不会被调度到dev-k8s-m1这个节点
删除taint
1 | kubectl taint nodes dev-k8s-m1 role.kubernetes.io/controlplane:NoSchedule- |
点污点是与“effect”相关联的键值对。以下是可用的effect:1
2
3NoSchedule:不会将不能容忍此污点的 Pod 调度到节点上。
PreferNoSchedule:Kubernetes 会避免将不能容忍此污点的 Pod 调度到节点上。这是一个优先选择或者软性版本的NoSchedule,调度系统会尽量避免调度不容忍这种污点的pod到带有此污点的节点上,但是并不是硬性要求
NoExecute:如果 Pod 已在节点上运行,则会将该 Pod 从节点中逐出;如果尚未在节点上运行,则不会将其调度到节点上。
toleration
可以在 PodSpec 中定义 pod 的 toleration。下面两个 toleration 均与上面例子中使用 kubectl taint 命令创建的 taint 相匹配,因此如果一个 pod 拥有其中的任何一个 toleration 都能够被分配到 dev-k8s-m11
2
3
4
5tolerations:
- key: "role.kubernetes.io/controlplane"
operator: "Equal"
value: "true"
effect: "NoSchedule"
1 | tolerations: |
只有pod的key和effect都和某一个污点的key与effect匹配,才被认为是匹配,并且要符合以下情形:
operator是Exists(这种情况下value不应当指定)
operator是 Equal 并且value相同
如果operator没有指定,则默认是Equal1
2
3
4
5
6tolerations:
- operator: "Exists"
tolerations:
- key: "role.kubernetes.io/controlplane"
operator: "Exists"
以上会匹配所有key为role.kubernetes.io/controlplane的所有taint节点
可以为一个节点(node)添加多个污点,也可以为一个pod添加多个容忍(toleration).kubernetes处理多个污点(taint)或者多个容忍(toleration)类似于过滤器:起初包含所有污点,然后忽略掉pod匹配的污点,剩下不可被忽略的污点决定此节点对pod的效果,特别地:
1 如果至少有一个不可忽略的NoSchedule类型的效果(effect),kubernetes不会调度pod到此节点上来.
2 如果没有不可忽略的NoSchedule类型的效果(effect),但是至少有一个PreferNoSchedule类型的效果,则kubernetes会尝试调度pod到此节点上
3 如果至少有一个NoExecute类型的效果(effect),则此pod会被驱离此节点(当然,前提此pod在此节点上),并且如果pod不在此节点上,也不会被调度到此节点上
假如你有一个以下类型的节点1
2
3kubectl taint nodes node1 key1=value1:NoSchedule
kubectl taint nodes node1 key1=value1:NoExecute
kubectl taint nodes node1 key2=value2:NoSchedule
类型的pod1
2
3
4
5
6
7
8
9tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
这种情况下,pod不会被调度到node1上,因为没有容忍(toleration)来匹配第三个taint.但是如果它运行在此节点上,它仍然可以继续运行在此节点上,因为它仅仅不匹配第三个taint.(而第三个taint的效果是NoSchedule,指示不要被调度到此节点)
tolerationSeconds
通常情况下,一个效果类型为NoExecute的taint被添加到一个节点上后,所有不容忍此taint的pod会被马上驱离,容忍的永远不会被驱离.但是效果类型NoExecute可以指定一个tolerationSeconds字段来指示当NoExecute效果类型的污点被添加到节点以后,pod仍然可以继续在在指定时间内留存在此节点上,优雅驱离1
2
3
4
5
6tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
在此段时间内如果污点被移除,则pod不会被驱离
ingress-nginx后端pod容器获取客服端真实ip
业务场景:
cdn-LB-ingress-nginx
创建ingres-nginx的configmap文件1
2
3
4
5
6
7
8
9
10
11
12
13kubectl apply -f - <<EOF
apiVersion: v1
data:
compute-full-forwarded-for: "true"
forwarded-for-header: X-Forwarded-For
use-forwarded-headers: "true"
kind: ConfigMap
metadata:
labels:
app: ingress-nginx
name: nginx-configuration
namespace: ingress-nginx
EOF
主要参数https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#use-forwarded-headers1
2
3compute-full-forwarded-for: "true"
forwarded-for-header: X-Forwarded-For
use-forwarded-headers: "true"
关于docker overlay2存储驱动配置
为啥要用overlay2
docker centos(内核3.10)上默认存储驱动是devicemapper 的loop-lvm模式,这种模式是用文件模拟块设备,不推荐生产使用
direct lvm又不是一个开箱即用的模式,懒得配置
最关键的是 docker in docker的情况下 device mapper是行不通的,典型的场景就是用drone时,构建docker镜像就不能正常工作
overlay存储驱动层数过多时会导致文件链接数过多可能会耗尽inode
所以当前overlay2是个比较好的选择
内核
你需要一个高版本的内核推荐4.9以上,我们用的是4.14,如果使用低内核可能你一些FROM别的基础镜像就跑不了,如用overlay2在centos系统上跑FROM ubuntu的镜像(不是必现)
我们这里提供了一个免费的内核rpm包 这个在我们生产环境跑了将近一年没出任何问题
监控
overlay2如果不做一些特殊操作,cadvisor是监控不到容器内实际使用多少磁盘的,经过xfs和配额配置才能正常监控到
kubernetes
kubelet默认一次拉取一个镜像,设置为false可以同时拉取多个镜像,
前提是存储驱动要为overlay2,对应的Dokcer也需要增加下载并发数
serialize-image-pulls: ‘false’
使用xfs文件系统
不使用xfs就无法做到给每个容器限制10G的大小,就可能出现一个容器的误操作导致把机器盘全占完
我们使用了lvm去弄个分区出来做xfs文件系统,当然你也可以不用lvm1
2
3
4
5
6
7
8
9if which lvs &>/dev/null; then
echo ""; echo -e "Remove last docker lv and mount ......"
lvremove k8s/docker -y
lvcreate -y -n docker k8s -L 100G
mkfs.xfs -n ftype=1 -f /dev/mapper/k8s-docker
mkdir -p /var/lib/docker
mount -o pquota,uqnoenforce /dev/mapper/k8s-docker /var/lib/docker
echo -e "/dev/mapper/k8s-docker /var/lib/docker xfs defaults,pquota 0 0" >> /etc/fstab
fi
配置使用overlay2
1 | # cat /etc/docker/daemon.json |
这样就可以把每个容器磁盘大小限制在10G了
Nginx常用配置笔记
location匹配规则及优先级
- = 严格匹配这个查询。如果找到,停止搜索。
- ^~ 匹配路径的前缀,如果找到,停止搜索。
- ~ 为区分大小写的正则匹配
- ~ 为不区分大小写匹配
优先级: =, ^~, ~/~, 无
Nginx禁止未绑定域名访问
nginx通过host配置确认转发到那台服务器处理。如果未匹配上就会转发到default_server节点来处理。例如配置如下:1
2
3
4server {
listen 80 default_server;
server_name nginx.net;
}
对于所有请求的HOST未匹配上的都会转发到该server处理。
通过如下配置,所有未匹配到server_name的请求都会返回4031
2
3
4
5server{
listen 80 default;
server_name _ ;
return 403;
}
其中_是无效域名的代表,同样可以写成其他例如”-” “@”等等。
Nginx rewrite配置
1)last
重新将rewrite后的地址在server标签中执行
2)break
将rewrite后的地址在当前location标签中执行
3)redirect
返回302临时重定向,浏览器地址会显示跳转后的URL地址。
4)permanent
返回301永久重定向,浏览器地址会显示跳转后的URL地址。
使用last和break,浏览器中的地址不会改变,其中需要注意的是last和break的区别:
使用alias指令必须用last标记;使用proxy_pass指令时,需要使用break标记。Last标记在本条rewrite规则执行完毕后,会对其所在server{……}标签重新发起请求,而break标记则在本条规则匹配完成后,终止匹配。
将url中以/wap/开头的请求转发到后台对应的某台server上,可以再Nginx里设置一个变量,来临时保存/wap/后面的路径信息
1 | location ^~ /wap/ |
注意上面最后的?$args,表明把原始url最后的get参数也给代理到后台
如果在proxy_pass中使用了变量(不管是主机名变量$1或后面的$2变量),则必须得加这段代码
但如果proxy_pass没用任何变量,则不需要加,它默认会把所有的url都给代理到后台,如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28location ~* /wap/(\d+)/(.+)
{
proxy_pass http://mx.test.com:6601;
}
另外还需要注意url的/问题
下面四种情况分别用http://192.168.1.4/proxy/test.html 进行访问。
第一种:
location /proxy/ {
proxy_pass http://127.0.0.1:81/;
}
会被代理到http://127.0.0.1:81/test.html 这个url
第二种(相对于第一种,最后少一个 /)
location /proxy/ {
proxy_pass http://127.0.0.1:81;
}
会被代理到http://127.0.0.1:81/proxy/test.html 这个url
第三种:
location /proxy/ {
proxy_pass http://127.0.0.1:81/ftlynx/;
}
会被代理到http://127.0.0.1:81/ftlynx/test.html 这个url。
第四种情况(相对于第三种,最后少一个 / ):
location /proxy/ {
proxy_pass http://127.0.0.1:81/ftlynx;
}
会被代理到http://127.0.0.1:81/ftlynxtest.html 这个url
也就是说如果proxy_pass只是后端服务器的IP,最后没有/的话,就会将全uri带过去。
而如果proxy_pass带了/的话,只是带最后访问的文件。
root与alias区别
一句话概括,root对应的目录会加上location部分去找文件,而alias则不会
Nginx 配置文件 server 中指定两个 location 执行,分别为root 和 alias 指令:
alisa:1
2
3location /static/ {
alias /www/test/;
}
按照上述配置,则访问 /static/ 目录里面的文件时,nginx 会去 /www/test/ 目录找文件
请求 http://idcsec.com/static/a.gif 时,在服务器查找的资源路径是:/www/test/a.gif
root:1
2
3location /static/ {
root /www/test;
}
按照这种配置,则访问 /static/ 目录下的文件时,nginx 会去 /www/test/static/ 目录下找文件
请求 http://idcsec.com/static/a.gif 这个地址时,那么在服务器里面对应的真正的资源是 /www/test/static/a.gif文件,真实的路径是root指定的值加上location指定的值
- alias 是一个目录别名的定义,root 则是最上层目录的定义。
- 另一个区别是 alias 后面必须要用 “/” 结束,否则会找不到文件,而 root 则对 ”/” 可有可无。
- 误区:认为 root 是指 /www/test目录下,而应该是 /www/test/static 目录 。
Nginx静动分离1
2
3
4
5
6location ~ .*\.(html|htm|gif|jpg|jpeg|bmp|png|ico|txt|js|css)$
{
root /usr/local/nginx/html/website/static/;
#expires定义用户浏览器缓存的时间为7天,如果静态页面不常更新,可以设置更长,这样可以节省带宽和缓解服务器的压力
expires 1d;
}
Nginx日志 切割1
2
3
4
5
6
7
8
9#nginx日志切割脚本
#!/bin/bash
logs_path="/usr/local/nginx/logs/"
pid_path="/usr/local/nginx/logs/nginx.pid"
mv ${logs_path}access.log ${logs_path}access_$(date -d "yesterday" +"%Y%m%d").log
kill -USR1 `cat ${pid_path}`
crontab -e
0 0 * * * bash /usr/local/nginx/nginx_log.sh
Nginx 443强制跳转1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29server {
listen 443;
server_name idcsec.com.com;
ssl on;
ssl_certificate /etc/nginx/ssl/idcsec.com.crt;
ssl_certificate_key /etc/nginx/ssl/idcsec.com.com.key;
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 5m;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
proxy_pass http://test_domain;
proxy_next_upstream error timeout invalid_header http_500 http_502 http_503;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto https;
proxy_redirect off;
}
}
server {
listen 80;
server_name idcsec.com.com;
location / {
return 301 https://$server_name$request_uri;
}
}
fastDFS单节点搭建
单机版搭建
安装依赖
1 | # yum install git gcc gcc-c++ make automake autoconf libtool pcre pcre-devel zlib zlib-devel openssl-devel -y |
创建数据目录1
# mkdir -p /data/fastdfs/{tracker,storage}
下载安装包
安装libfatscommon
1 | git clone https://github.com/happyfish100/libfastcommon.git --depth 1 |
安装FastDFS
1 | git clone https://github.com/happyfish100/fastdfs.git --depth 1 |
配置文件生成1
2
3
4
5cp /etc/fdfs/tracker.conf.sample /etc/fdfs/tracker.conf #tarcker服务配置文件
cp /etc/fdfs/storage.conf.sample /etc/fdfs/storage.conf #storage服务配置文件
cp /etc/fdfs/client.conf.sample /etc/fdfs/client.conf #客户端文件,测试用
cp conf/http.conf /etc/fdfs/ #供nginx访问使用
cp conf/mime.types /etc/fdfs/ #供nginx访问使用
安装fastdfs-nginx-module需要在编译nginx时候添加这个模块1
2git clone https://github.com/happyfish100/fastdfs-nginx-module.git --depth 1
cp fastdfs-nginx-module/src/mod_fastdfs.conf /etc/fdfs/
安装nginx
1 | ~]# wget http://nginx.org/download/nginx-1.14.0.tar.gz |
tracker配置
1 | vim /etc/fdfs/tracker.conf |
storage配置
1 | vim /etc/fdfs/storage.conf |
检查fdfs状态
fdfs_monitor /etc/fdfs/storage.conf
配置nginx访问
vim /etc/fdfs/mod_fastdfs.conf1
2
3
4需要修改的内容如下
tracker_server=192.168.1.38:22122
url_have_group_name=true
store_path0=/data/fastdfs/storage
1 | vi /usr/local/nginx/conf/nginx.conf |
vim /etc/fdfs/client.conf
修改的内容如下
1 | base_path=/data/fastdfs/tracker |
1 | [root@ecs-1d0e ~]# fdfs_upload_file /etc/fdfs/client.conf /root/1.txt |
FastDFS 防盗链开启
但是这样是不安全的,因为只要知道ip和文件路径,就能下载所需文件。因此采用Token方式防盗链。
cp /root/fastdfs/conf/anti-steal.jpg /etc/fdfs/
vim /etc/fdfs/http.conf1
2
3
4
5#开启token校验
http.anti_steal.check_token=true
#设置校验失败后显示的警告图片
http.anti_steal.token_check_fail=/etc/fdfs/anti-steal.jpg
重启nginx
Istio配置之配置ingress流量Gateway暴露服务提供外部访问
注意:此任务使用新的 v1alpha3 流量管理 API。旧的 API 已被弃用,ngress Gateway 组件替代了符合 Kubernetes 规范的 Ingress Controller,因此对入站流量具有了更大的控制能力。
1、创建pod应用,确保namespace开启自动注入Pod所在的namespace包含istio-injection=enabled的Label
否则就必须在部署 tomcatapp应用程序之前手动注入 Sidecar1
kubectl apply -f <(istioctl kube-inject -f tomcat-demo.yaml) //namespaceswei
1 | kubectl apply -f tomcat-demo.yaml |
创建Gateway1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17kubectl get svc -n istio-system -l istio=ingressgateway
cat <<EOF | istioctl create -f -
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: tomcatapp-gateway
spec:
selector:
istio: ingressgateway # use Istio default gateway implementation
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "tomcat.idcsec.com"
EOF
1 | 创建VirtualService组绑定网关 |
接下来就可以在浏览器的访问域名自行修改host或者使用curl
一个简单使用IstioGateway 配置资源允许外部流量进入 Istio 服务网就完成
清理
删除 Gateway 和 VirtualService,并关闭 tomcat-demo 服务:1
2
3$ istioctl delete gateway tomcatapp-gateway
$ istioctl delete virtualservice tomcat-istio
$ kubectl delete --ignore-not-found=true -f tomcat-demo.yaml
kubernetes部署网格服务Istio
安装Istio
1 | curl -L https://git.io/getLatestIstio | sh - |
将在运行上述命令的同一目录中找到一个文件夹istio-1.0.6。将位置istio-1.0.6/ bin添加到PATH变量,以便于访问Istio二进制文件。
将Ingress Gateway服务从LoadBalancer类型更改为NodePort
Istio为Kubernetes提供了许多自定义资源定义(CRD)。它们帮助我们从kubectl操纵虚拟服务,规则,网关和其他特定于Istio的对象。让我们在部署实际服务网格之前安装CRD。1
kubectl apply -f install/kubernetes/helm/istio/templates/crds.yaml
查看安装的CRD:1
kubectl get CustomResourceDefinition
Kubernetes中安装Istio核心组件1
kubectl apply -f install / kubernetes / istio-demo.yaml
1 | kubectl get svc -n istio-system -l istio=ingressgateway |
*当前EXTERNAL-IP处于pending状态,为了使得可以从外部访问,修改istio-ingressgateway这个Service的externalIps,所以这个指定一个192.168
.19.223作为externalIp。也是可以设置NodePort 通过节点的nodeip:PORT访问1
2
3[root@k8s-master istio-1.0.6]# kubectl get svc -n istio-system -l istio=ingressgateway
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
istio-ingressgateway LoadBalancer 10.102.137.201 192.168.19.223 80:31380/TCP,443:31390/TCP,31400:31400/TCP,15011:31211/TCP,8060:31598/TCP,853:31745/TCP,15030:30600/TCP,15031:30012/TCP 2m21s
验证安装1
2kubectl get svc -n istio-system
kubectl get pod -n istio-system
部署Bookinfo应用自动注入sidecar
kubectl get pod -n istio-system | grep injector
istio-sidecar-injector可以自动将Envoy容器作为sidecar注入到Pod中,Pod所在的namespace包含istio-injection=enabled的Label。1
2
3kubectl label namespace default istio-injection=enabled
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
kubectl apply -f samples/bookinfo/platform/kube/bookinfo-ingress.yaml
1 | [root@k8s-master istio-1.0.6]# kubectl get pod,svc | grep -vE "tomcat|iperf" |
通过Istio Ingress Gateway暴露Bookinfo应用
创建bookinfo的Gateway和VirtualService:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41[root@k8s-master istio-1.0.6]# cat samples/bookinfo/networking/bookinfo-gateway.yaml
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: bookinfo-gateway
spec:
selector:
istio: ingressgateway # use istio default controller
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: bookinfo
spec:
hosts:
- "*"
gateways:
- bookinfo-gateway #对应上面的网关名称
http:
- match:
- uri:
exact: /productpage
- uri:
exact: /login
- uri:
exact: /logout
- uri:
prefix: /api/v1/products
route:
- destination:
host: productpage
port:
number: 9080
kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
1 | [root@k8s-master istio-1.0.6]# kubectl get gateway |
访问http://192.168.19.223/productpage
临时映射grafana端口1
kubectl -n istio-system port-forward --address 0.0.0.0 $(kubectl -n istio-system get pod -l app=grafana -o jsonpath='{.items[0].metadata.name}') 3333:3000 &
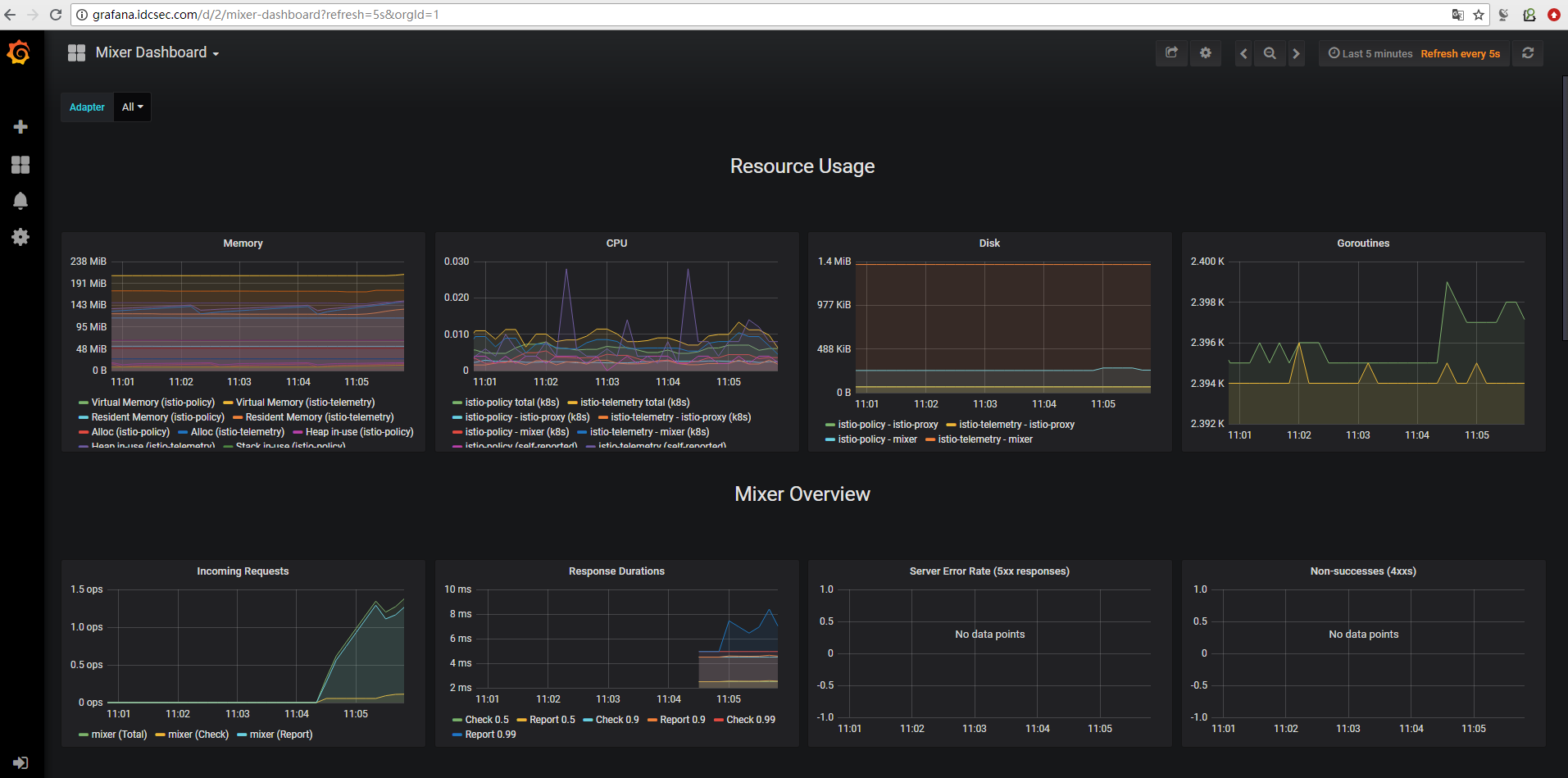
使用 Istio 网关配置 Ingress暴露grafana服务
Ingress Gateway描述了在网格边缘操作的负载平衡器,用于接收传入的 HTTP/TCP 连接。它配置暴露的端口,协议等,但与 Kubernetes Ingress Resources 不同,它不包括任何流量路由配置。流入流量的流量路由使用 Istio 路由规则进行配置,与内部服务请求完全相同。
创建一个 Istio Gateway:
1 | cat <<EOF | istioctl create -f - |
为通过 Gateway 进入的流量配置路由创建VirtualService:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21cat <<EOF | istioctl create -f -
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: grafana
namespace: istio-system
spec:
hosts:
- "grafana.idcsec.com"
gateways:
- grafana-gateway
http:
- match:
- uri:
prefix: /
route:
- destination:
port:
number: 3000
host: grafana
EOF
使用浏览器访问 Ingress 服务
在浏览器中输入 grafana 服务的地址是不会生效的,这是因为因为我们没有办法让浏览器像 curl 一样装作访问grafana.idcse.com。因为有正常配置的主机和 DNS 记录,这种做法就能够成功了——只要简单的在浏览器中访问由域名构成的 URL 即可,例如 http://grafana.idcse.com/。
要解决此问题以进行简单的测试和演示,我们可以在 Gateway 和 VirutualService 配置中为hosts:使用通配符值 *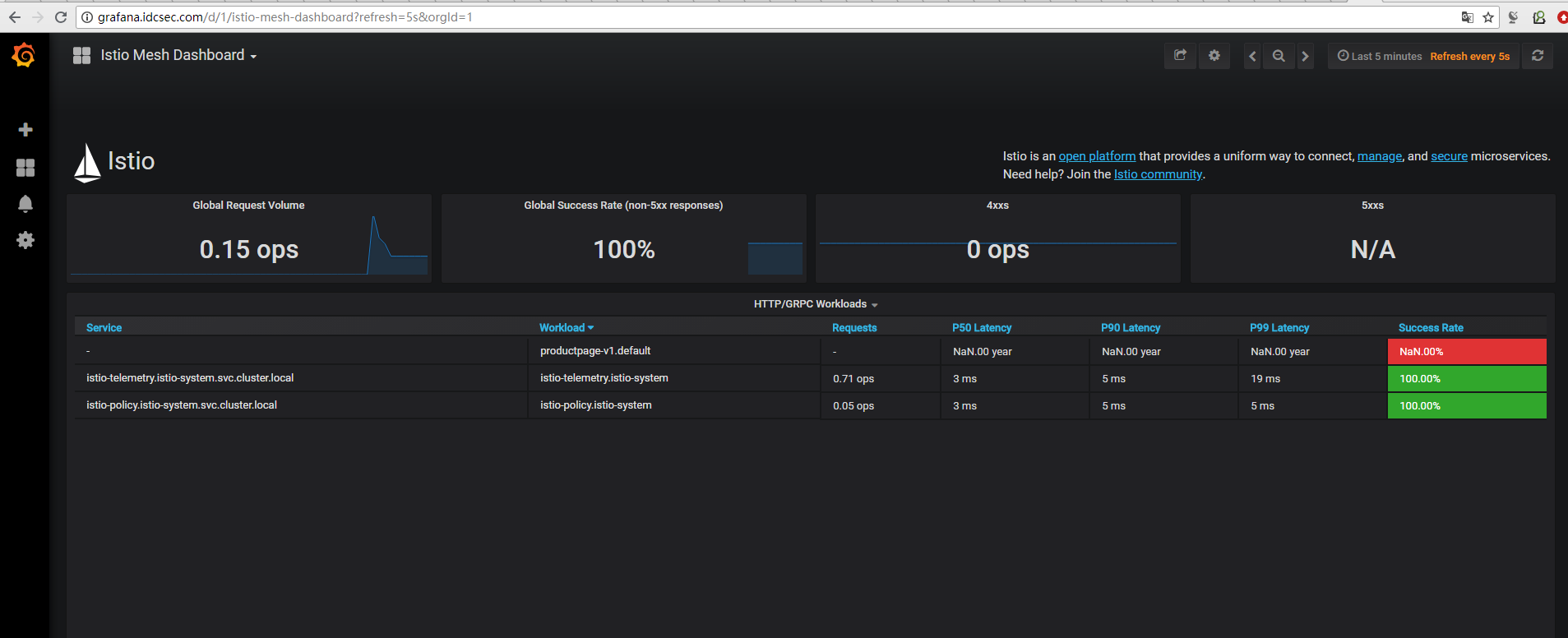
删除 Gateway 和 VirtualService,并关闭 httpbin 服务:
·····
$istioctl delete gateway grafana-gateway
$ istioctl delete virtualservice grafana
····
卸载Istio
···
kubectl delete -f install/kubernetes/istio-demo.yaml
kubectl delete -f install/kubernetes/helm/istio/templates/crds.yaml -n istio-system
···
tomcat配置获取kubernetes自定义变量
tomcat获取kubernetes自定义变量
1、设置kubernetes自定义变量MY_POD_NAME
2、设置tomcat的JAVA_OPTS -D自定义变量名称:值(yaml里面定义的变量)
3、tomcat配置文件引用变量,获取kubernetes的pod主机名,处理多个pod日志按照主机名命名解决日志交叉写入
1 | [root@k8s-master ~]# cat tomcat-demo.yaml |
1 | DOckerfile |