一、filebeat
k8s日志收集方案使用官方推荐的EFK方案F(fluentd),部分宿主机日志使用filebeat
filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh、kafka、redis中存放。Filebeat 所占系统的 CPU 和内存几乎可以忽略不计,filebeat使用Go语言开发运行不依赖环境。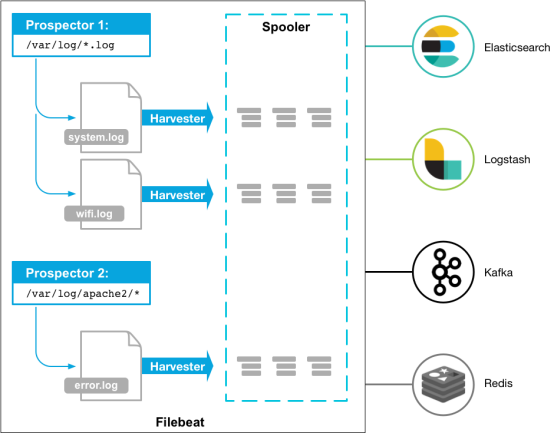
EFK 环境应该部署好,这里主要记录filrbeat-kafka-logstash-es-kibana
下载安装filebeat
1 | curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.5.4-x86_64.rpm |
filebeat配置文件
cat filebeat.yml1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47############################# Filebeat inputs #########################################
filebeat.inputs:
- input_type: log
enabled: true
paths:
- /opt/tomcat7credit/clsp/Application.* #日志文件路径可以使用正则表匹配
encoding: GB2312 #编码解决tomcat使用非utf-8乱码问题
tags: ["tomcatlogs"]
multiline.pattern: ^\d{4} #多行合并解决tomcat错误堆栈日志
multiline.negate: true
multiline.match: after
multiline.max_lines: 800
multiline.timeout: 1
document_type: xxxapplication #新版本已经取消资格type
# 如果设置为trueFilebeat从文件尾开始监控文件新增内容把新增的每一行文件作为一个事件依次发送而不是从文件开始处重新发送所有内容。
tail_files: true
backoff: 1s
fields: #添加一个标签fields.appname
appname: xxxapplication
- input_type: log
enabled: true
paths:
- /opt/tomcat7thirdtask/thirdtask/apilog.log
encoding: GB2312
multiline.pattern: ^\d{4}
multiline.negate: true
multiline.match: after
multiline.max_lines: 800
multiline.timeout: 1
document_type: thirdtaskapilog
# 如果设置为trueFilebeat从文件尾开始监控文件新增内容把新增的每一行文件作为一个事件依次发送而不是从文件开始处重新发送所有内容。
tail_files: true
backoff: 1s
fields:
appname: thirdtaskapilog
############################# output kafka #########################################
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["192.168.200.102:9092","192.168.200.102:9093","192.168.200.102:9094"]
enabled: true
# message topic selection + partitioning
topic: 'Applicationlogs'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000
之前版本使用filebeat.prospectors:
配置logstash消费kafka的topic:Applicationlogs信息
1 | input { |
如果kibana创建index完成。
获取日志时间字段替换es里面的@timestamp字段
例如日志格式1
2019-01-09 17:23:27 [ http-bio-8080-exec-151:67436064 ] - [ INFO ] com.crfchina.p2p.finance.service.dao.hibernate.P2pAccountInfoDaoImpl.queryReserver(P2pAccountInfoDaoImpl.java:2613) 查询状态为1的结果!
通过http://grokdebug.herokuapp.com/ 测试解析字段1
%{TIMESTAMP_ISO8601:time}\s\[\s*%{JAVAFILE:class}:%{NUMBER:lineNumber}\s*\]\s*-\s*\[\s*%{LOGLEVEL:level}\s*\]\s(?<msg>([\s\S]*))
配置logstash通过filter-grok解析字段
安装插件1
/usr/share/logstash/bin/logstash-plugin install logstash-filter-grok logstash-filter-date
添加filter配置从字段里分析日期格式,然后放入@timestamp字段里。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24### FILTERS
filter {
if [fields][appname] == "xxxapplication"{
grok {
#获取xxxapplication 日志字段
match => {
"message" => [
#xxxapplication格式
'%{TIMESTAMP_ISO8601:time}\s\[\s*%{JAVAFILE:class}:%{NUMBER:lineNumber}\s*\]\s*-\s*\[\s*%{LOGLEVEL:level}\s*\]\s(?<msg>([\s\S]*))'
]
}
true}
date {
truematch => [ "time","yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
true}
true #移除原有数据
#remove_field => ["timestamp"]
#remove_field => [ "message" ]
mutate {
remove_field =>["message"]
}
}
}
tomcatcatalina日志1
2019-01-10 04:51:59.589 default [scheduler_Worker-1] INFO com.zhph.third.utils.BatchCheck - 第0次请求跑批记录控制请求参数:{"startTime":"2019-01-10 04:00:22","runResult":"0","batchName":"magicReportDaily","sysName":"thirdtask","comment":"成功执行跑批","endTime":"2019-01-10 04:51:59"}
对应grok1
%{TIMESTAMP_ISO8601:time}\s(?<default>[a-z]{7})\s\[%{JAVAFILE:class}\]\s%{LOGLEVEL:level}\s\s%{GREEDYDATA:message}
tomcatcatalina日志1
2016-10-22 20:59:22,877 INFO com.zjzc.interceptor.ClientAuthInterceptor - authInfo servletPath=/validate/code/send,clientSn=null,access=true",
对应grok1
%{TIMESTAMP_ISO8601:time}\s+(?<Level>(\S+))%{GREEDYDATA:message}
tomcat logs日志
filebea配置1
2
3
4
5
6
7
8
9- input_type: log
enabled: true
paths:
- /opt/tomcat8/localhost_access_log.*
# 如果设置为trueFilebeat从文件尾开始监控文件新增内容把新增的每一行文件作为一个事件依次发送而不是从文件开始处重新发送所有内容。
tail_files: true
backoff: 1s
fields:
appname: tomcataccess
修改tomcat配置文件server.xml1
2
3
4
5
6 <Valve className="org.apache.catalina.valves.AccessLogValve"
directory="logs" prefix="access_log"
suffix=".log" rotatable="true" resolveHosts="false"
pattern="%h %l %u %t [%r] %s [%{Referer}i] [%{User-Agent}i] %b %T" />
</Host>
日志参数说明
http://tomcat.apache.org/tomcat-8.5-doc/config/valve.html#Access_Logging1
2
3
4
5
6
7
8
9
10%h 访问的用户IP地址
%l 访问逻辑用户名,通常返回'-'
%u 访问验证用户名,通常返回'-'
%t 访问日时
%r 访问的方式(post或者是get),访问的资源和使用的http协议版本
%s 访问返回的http状态
%b 访问资源返回的流量
%T 访问所使用的时间
[%{Referer}i]
[%{User-Agent}i]
格式1
10.10.0.100 - - [04/Sep/2018:19:54:07 +0800] [GET / HTTP/1.1] 200 [-] [Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36] 5 0.104
grok过滤1
JETTYAUDIT %{IP:clent_ip} (?:-|%{USER:logic_user}) (?:-|%{USER:verification_user}) \[%{HTTPDATE:timestamp}\] \[(?:%{WORD:http_verb} %{NOTSPACE:request_url}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\] %{NUMBER:status} \[(?:-|%{NOTSPACE:request_url_2})\] \[%{GREEDYDATA:agent}\] (?:-|%{NUMBER:curl_size}) (?:-|%{NUMBER:responsetime})
1 | grok { |
如果默认tomcatgrok格式1
2
3
4
5
6
7
8
9
10
11filter {
if [fields][appname] == "tomcataccess"{
grok {
match => {
"message" => ["message","%{IPORHOST:clientip} %{USER:ident} %{DATA:auth} \[%{HTTPDATE:timestamp}\] \"(%{WORD:verb} %{NOTSPACE:request} (HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})\" %{NUMBER:response} (%{NUMBER:bytes})"]
}
}
date {
match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}